

{kind=link}
I’ve been intently following how rapidly the world of LLMs is evolving, and one space that basically excites me is the rise of subtle Coverage Optimization Methods. What stood out to me just lately is DeepSeek-R1, which leverages GRPO to ship exceptional efficiency in reinforcement studying. It appears like a glimpse into the longer term: as AI methods grow to be extra succesful and complicated, the strategies we use to optimize them can’t stay static. Conventional approaches are already beginning to hit their limits. Newer strategies like GRPO present us how we’d unlock the following stage of functionality and alignment in AI.
What’s GRPO?
Group Relative Coverage Optimization (GRPO) is a brand new strategy to coverage optimization for big language fashions. In contrast to conventional strategies that optimize insurance policies in isolation, GRPO permits insurance policies to optimize relative to teams of comparable contexts or circumstances.
GRPO addresses a key problem in Reinforcement Studying (RL), balancing exploration and exploitation whereas staying steady in opposition to the variability of coaching examples. It does this by:
- Grouping examples the place context and rewarded conduct are related
- Optimizing insurance policies relative to group efficiency somewhat than solely metric efficiency
- Sustaining consistency inside contexts whereas permitting specialised adaptation
- Decreasing variance in coverage updates by means of group normalization
This allows extra context-aware studying for insurance policies in Giant Language Fashions (LLMs), which should deal with a variety of behaviors throughout numerous contexts.
[43] # Simplified GRPO Implementation Idea
class GRPO:
def init (self, mannequin, group dimension=8, relative threshold=0.1):
self.mannequin = mannequin
self.group dimension = group dimension
self.relative threshold = relative threshold
self.expertise buffer = []
def group_experiences(self, experiences) :
“""Group experiences by contextual similarity""*
teams = []
for exp in experiences:
# Compute embedding for context similarity
context_embedding = self.mannequin encode (exp. context)
# Discover or create applicable group
assigned = False
for group in teams:
if self.compute similarity (context embedding, group.centroid) > 0.
group .add(exp)
assigned = True
break
if not assigned:
teams .append ( ExperienceGroup( texp]))
return teams
def compute relative benefit(self, group):
"""Compute benefits relative to group efficiency"""
group baseline = np.imply([exp.reward for exp in group.experiences])
relative benefits = []
for exp in group.experiences:
relative adv = exp.reward - group baseline
relative benefits .append(relative adv)
return relative_advantagesWhy is GRPO Vital?
GRPO is very related in right now’s AI panorama. As LLMs develop in scale and complexity, conventional coverage optimization strategies face limitations throughout three main challenges that GRPO goals to deal with:
- Pattern Effectivity Disaster: Conventional strategies typically require very giant datasets to converge reliably. GRPO’s group-based strategy improves effectivity by pooling observations inside batches, figuring out relative patterns throughout related contexts, and enabling fashions to be taught successfully with fewer examples.
- Catastrophic Forgetting: Normal Reinforcement Studying (RL) strategies wrestle to retain confirmed behaviors when launched to new contexts. GRPO’s relative optimization enforces group-based consistency, permitting fashions to adapt whereas sustaining efficiency throughout broader classes.
- Reward Sparsity: Many real-world purposes contain delayed or sparse rewards, making absolute efficiency troublesome to measure. GRPO helps fashions interpolate relative group efficiency, enabling studying even when rewards are rare.
Given the dimensions at which LLMs now function; spanning artistic writing, reasoning, arithmetic, and even emotional intelligence; the flexibility to stay constant and dependable throughout numerous contexts makes GRPO a essential development.
From PPO to GRPO: The Development of Coverage Optimization
Coverage Optimization Methods have naturally progressed over time, and understanding this development makes it clear why GRPO has emerged as a crucial resolution for contemporary LLMs.
- PPO: When PPO was launched, it reshaped how the group thought of environment friendly RL with its clipped goal perform, which helped forestall overly giant, damaging updates. Whereas efficient, PPO treats all coaching examples equally, ignoring similarities that might characterize significant contextual groupings.
# Conventional PPO Loss Operate
def ppo_loss(old_probs, new_probs, benefits, clip_ratio=0.2):
ratio = new_probs / old_probs
clipped_ratio = torch.clamp(ratio, 1 - clip_ratio, 1 + clip_ratio)
loss = -torch.min(ratio * benefits, clipped_ratio * benefits)
return loss.imply()- GRPO: GRPO builds on PPO by addressing this limitation. As a substitute of assuming all experiences are proportionate, it optimizes teams of comparable examples collectively. This group-relative strategy makes coaching extra context-aware and improves coverage efficiency.
# GRPO Enhanced Loss Operate
def grpo_loss(teams, clip_ratio=0.2, group_weight=0.3):
total_loss = 0
for group in teams:
# Compute group-relative benefits
group_advantages = compute relative benefit(group)
# Conventional PPO loss inside group
ppo_group_loss = ppo_loss(
group.old_probs,
group.new_probs,
group_advantages,
clip_ratio
)
# Group consistency time period
consistency loss = compute group consistency(group)
# Mixed loss
group_loss = ppo_group_loss + group_weight * consistency loss
total_loss += group_loss
return total_loss / len(teams)This shift from PPO to GRPO is not only a technical tweak however an evolution; from treating all experiences uniformly to adopting a extra structured, context-sensitive strategy.
Workflow of GRPO: A Deep Dive
Group Relative Coverage Optimization (GRPO) is a coordinated workflow the place a number of elements work together to attain greater than any single Reinforcement Studying (RL) methodology can ship alone. Earlier than exploring the phases and limitations of the GRPO workflow, it’s helpful to grasp the core processes it employs; this helps clarify how fashions like DeepSeek-R1 obtain their distinctive CSER capabilities.
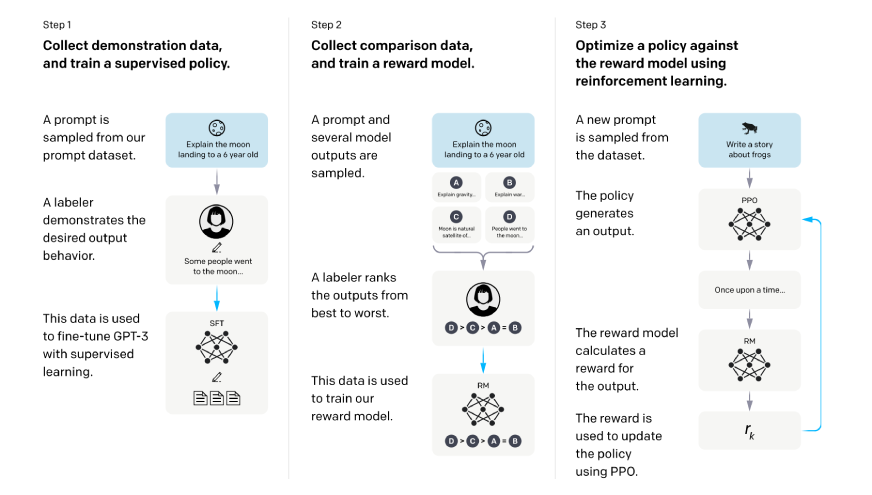
Part 1: Expertise Assortment and Preprocessing
The GRPO workflow begins with a set of experiences (interplay knowledge) of how the LLMs interacted. Right here, and extra importantly than our prior, GRPO collects experiences of the LLMs in a means that’s delicate not solely to the input-output pairs, but additionally contemplating contextual metadata that specifies the context with which the brokers will determine their grouping actions.
Part 2: Dynamic Grouping
That is the step that separates GRPO from the previous efforts (in RL) because the system digests the experiences collected through the first part, employs much more subtle embedding as understanding embeddings to find pure grouping of comparable experiences. The grouping algorithm incorporates relative attributes of the next;
- Semantic similarity of the enter contexts
- Distribution of the rewards
- Complexity of duties
- Temporal proximity of the experiences
Part 3: Relative Benefits Calculation
For each grouping, GRPO calculates the benefits relative to the efficiency baseline of the group and to not a baseline of your entire inhabitants. With this primary potential artifact of aware grouping, we will nonetheless execute to some extent our talents to average conceptions of nuance in what is going to represent good efficiency in varied contexts.
Part 4: Group-Conscious Coverage Updates
The final part includes coverage replace utilizing the calculated relative benefits whereas sustaining related uniformity inside teams and throughout teams to make sure that efficiency enhancements in a single group don’t result in efficiency degradation in others.
# Full GRPO Workflow Implementation
class GRPOTrainer:
def init__(self, mannequin, config)
self.mannequin = mannequin
self.config = config
self.group_encoder = ContextualGroupEncoder()
self.advantage_computer = RelativeAdvantageComputer ()
def train_step(self, batch):
# Part 1: Preprocess experiences
experiences = self.preprocess_batch(batch)
# Part 2: Kind teams dynamically
teams = self.group_encoder.form_groups (experiences)
# Part 3: Compute relative benefits
for group in teams
group.benefits = self.advantage_computer.compute(group)
# Part 4: Replace coverage with group consciousness
loss = self.compute_grpo_loss(teams)
# Backpropagation and optimization
self .optimizer.zero_grad()
loss. backward()
self.optimizer.step()
return {
"loss': loss.merchandise(),
‘num_groups': len(teams),
‘avg_group_size': np.imply([len(g) for g in groups])Additionally Learn: A Information to Reinforcement Wonderful-tuning
How DeepSeek-R1 Used GRPO?
DeepSeek-R1’s Group Relative Coverage Optimization (GRPO) is taken into account one of the superior purposes of this method in Giant Language Fashions (LLMs). Past implementation, new architectural options permit GRPO to combine seamlessly throughout the mannequin. DeepSeek-R1 was developed in response to the constraints of conventional coverage optimization, aiming to deal with advanced reasoning duties with out sacrificing agility or consistency throughout numerous environments.
Multi-Scale Group Formation DeepSeek-R1 would componentize the hierarchy of groupings or nesting, that means they function at a number of scales without delay. Micro scale for instance – would imply combining particular person reasoning steps collectively throughout the intertices of advanced issues. Macro scale examples alternatively, imply combining complete classes of issues collectively. With multi-scale GRPO, DeepSeek-R1 is able to sustaining large-scale consistency throughout purposes whereas concurrently optimizing sub-components.
Along with having the ability to make a reasoning-aware confidence computation, DeepSeek-R1 additionally makes use of reasoning-aware metrics for calculating its benefit metric. Not solely does the system reward an accurate reply response throughout analysis of the reasoning course of, it additionally rewards the reasoning steps taken alongside the trail to a remaining reply, giving the system a chance to develop a reward sign that not solely values the ultimate reply, but additionally signifies the system to encourage higher cognitive processes alongside the way in which.
# DeepSeek-R1 Reasoning-Conscious GRPO
class DeepSeekGRPO:
def init__(self, reasoning mannequin, verifier_model):
self.reasoning mannequin = reasoning mannequin
self.verifier_model = verifier_model
self.reasoning teams = {}
def compute_reasoning aware_advantage(self, reasoning hint) :
“""Compute benefits contemplating reasoning high quality"""
steps = reasoning hint.decompose_steps()
step_scores = []
for step in steps:
# Rating particular person reasoning step
step_score = self.verifier_model.score_step(step)
step_scores.append(step_score)
# Discover related reasoning patterns in group
group_id = self.find_reasoning_group(reasoning hint)
group = self. reasoning teams[group_id]
# Compute relative benefit inside reasoning group
group_baseline = np.imply([trace.final_score for trace in group])
relative benefit = reasoning hint. final_score - group_baseline
# Weight by reasoning high quality
reasoning high quality = np.imply(step_scores)
weighted benefit = relative benefit * reasoning high quality
return weighted benefitDeepSeek-R1 Coaching Pipeline
The DeepSeek-R1 coaching pipeline integrates Group Relative Coverage Optimization (GRPO) inside a high-performing Giant Language Mannequin (LLM) framework, exhibiting how advances in Reinforcement Studying (RL) could be utilized in a scalable, sensible system.
- Pre-training Basis: The pipeline begins with pre-training on a curated dataset spanning a number of domains. In contrast to standard strategies, this stage prepares the mannequin for GRPO by together with reasoning traces and annotations of intermediate steps.
- GRPO Integration Layer: At its core, an integration layer combines the pre-trained mannequin with GRPO optimization, guaranteeing coherence whereas enabling group-specific variations.
- Multi-Goal Optimization: DeepSeek-R1 is educated with a framework balancing 5 targets:
- Accuracy: Ship right solutions.
- Reasoning high quality: Present clear, logical rationales.
- Processing effectivity: Decrease computational overhead.
- Consistency: Keep reliability throughout domains.
- Security: Stop biased or dangerous outputs.
- Ongoing Evaluation and Adjustment: The pipeline consists of monitoring instruments that monitor efficiency throughout numerous reasoning duties. These insights permit steady tuning of GRPO parameters and grouping methods, guaranteeing the mannequin maintains optimum efficiency because it evolves.
# DeepSeek-R1 Multi-Goal Coaching Pipeline
class DeepSeekRIPipeline:
def init__(self, base mannequin, config):
self.base mannequin = base mannequin
self.grpo_optimizer = GRPOOp: er(config.grpo)
self.multi_obj_balancer = Multi0bjectiveBalancer (config. goals)
self.security checker = SafetyVerifier()
def coaching epoch(self, dataset)
metrics = {
taccuracy': (1,
‘reasoning high quality’: [1,
‘efficiency’: [],
‘consistency’: [1,
"safety": []
}
for batch in dataset:
# Generate reasoning traces
traces = self.generate_reasoning_ traces (batch)
# Kind teams utilizing GRPO
teams = self.grpo optimizer. kind teams(traces)
# Multi-objective analysis
for group in teams:
group metrics = self.evaluate_group(group)
# Steadiness goals
balanced loss = self.multi_obj_balancer.compute_loss(
group_metrics
)
# Security filtering
safe_traces = self.security checker. filter(group.traces)
# Replace mannequin
self.replace mannequin (protected traces, balanced_loss)
# Observe metrics
for key, worth in group metrics. objects():
metrics [key] .append (worth)
return {ok: np.imply(v) for ok, v in metrics.objects()}What’s Superior GRPO?
As Group Relative Coverage Optimization (GRPO) evolves, researchers will develop Coverage Optimization Methods to new ranges of sophistication. Superior GRPO implementations might be particularly related for next-generation Giant Language Fashions (LLMs) and complicated Reinforcement Studying (RL) duties.
- Hierarchical Grouping Construction: Future GRPO methods will implement hierarchical groupings throughout a number of abstraction ranges. This can permit fashions to optimize accuracy inside small, centered in-context interactions whereas guaranteeing consistency throughout broader, associated teams.
- Adaptive Group Boundaries: As a substitute of fastened grouping, superior GRPO will outline boundaries dynamically, utilizing efficiency metrics and knowledge patterns to adapt group constructions in actual time.
- Cross-Group Information Sharing: Information switch between associated teams will grow to be integral, enabling fashions to leverage learnings from one context to optimize others. This cross-pollination will considerably enhance effectivity.
- Meta-Studying Linking: Probably the most superior GRPO methods will combine meta-learning, creating optimization processes that evolve over time. Such methods gained’t simply enhance job efficiency—they’ll additionally enhance their skill to learn to be taught.
# Superior GRPO with Hierarchical Construction
class AdvancedGRPO:
def init (self, mannequin, hierarchy depth=:
self.mannequin = mannequin
self.hierarchy depth = hierarchy depth
self.group hierarchy = self. initialize hierarchy()
self.transfer_networks = self.create transfer_networks()
def hierarchical _grouping(self, experiences
“""Create hierarchical group construction""
hierarchy = {}
for stage in vary(self.hierarchy depth) :
if stage == 0:
# Best granularity
teams = self.cluster_by similarity(experiences, threshold=0.9)
else:
# Coarser granularity
parent_groups = hierarchy[level-1]
teams = self.merge_similar_groups(parent_groups,
threshold=0.7*stage)
hierarchy[level] = teams
return hierarchy
def cross group switch(self, supply group, target_groups):
“Switch information between associated teams*"
supply patterns = self.extract_patterns (supply group)
switch weights = {}
for goal in target_groups:
similarity = self.compute group similarity(supply group, goal)
if similarity > 0.6:
switch weight = similarity * 0.3 # Managed switch
switch _weights[target.id] = switch weight
return transfer_weightsBenefits of GRPO
GRPO provides a number of benefits past efficiency positive factors in comparison with normal Coverage Optimization Methods. It represents a broader shift away from the pitfalls of conventional RL in Giant Language Fashions (LLMs) and supplies treatments to elementary challenges.
- Superior Pattern Effectivity: GRPO considerably improves pattern effectivity by leveraging similarities throughout experiences. This permits fashions to be taught from associated contexts whereas ignoring minor perturbations—essential given the price and scale of LLM coaching.
- Enhanced Stability and Robustness: Normal Coverage Optimization typically struggles with instability in high-dimensional motion areas. GRPO’s group-relative strategy introduces pure regularization, stopping excessive updates and retaining coaching steady.
- Contextual Adaptability: GRPO permits fashions to adapt to particular, context-dependent duties whereas sustaining general consistency. That is important for LLMs, which should deal with all the things from artistic writing to technical evaluation throughout numerous domains.
Limitations of GRPO
Though GRPO has clear advantages, it additionally comes with limitations which are necessary to contemplate when implementing it in LLMs or different RL methods.
- Computational Overhead: Group mechanics demand larger compute and reminiscence. The system should consider similarity, keep teams, and calculate relative benefits, including processing load.
- Group Formation Sensitivity: Efficiency relies upon closely on grouping strategies. Poor grouping can result in suboptimal or worse outcomes than normal approaches, requiring strong algorithms and experimentation.
- Hyperparameter Complexity: GRPO provides parameters for thresholds, group dimension, and relative benefits. Tuning them is time-consuming and sometimes requires skilled information.
- Area Switch Challenges: Whereas efficient in a single area, group constructions could not switch properly to very completely different domains; a key problem for LLMs working throughout numerous duties.
# GRPO Limitation Evaluation
class GRPOLimitationanalyzer:
def _ init__(self):
self.compute_profiler
self.group_quality assessor = G
self.hyperparameter_sensitivity =
HyperparameterSensitivityAnalyzer()
def analyze limitations(self, grpo_system, baseline system)
“analyze GRPO limitations in comparison with baseline"
# Computational Overhead Evaluation
overhead_analysis = self.compute_profiler.compare_overhead(
grpo_system, baseline system
)
# Group Formation High quality
group_quality = self.group_quality assessor.consider(
grpo_system. teams
)
# Hyperparameter Sensitivity
sensitivity evaluation = self.hyperparameter_sensitivity.analyze(
grpo_system. config
)
return {
‘computational_overhead': overhead_analysis,
"group formation high quality’: group_quality,
‘hyperparameter_ sensitivity’: sensitivity evaluation,
‘suggestions’: self.generate_mitigation_strategies()
}
def generate mitigation_strategies(self)
"""Generate methods to mitigate GRPO limitations"""
return [
"Implement efficient grouping algorithms with O(log n) complexity",
"use adaptive group size limits based on available resources",
"Employ automated hyperparameter optimization techniques",
“Implement group quality monitoring with fallback mechanisms"
]Use Instances
GRPO is inherently adaptable for a lot of Reinforcement Studying (RL) use circumstances, envisioning RL’s use circumstances will showcase GRPO as an distinctive Coverage Optimization Method. Following are some examples:
- Conversational AI Methods: GRPO is robust for coaching conversational AIs, which want to reply contextually and should keep away from variations between dialog varieties, and reply persistently with itself. Grouping permits a conversational AI to specialize for a number of dialog contexts (i.e., technical assist, artistic writing, schooling) whereas not permitting for damaging switch between domains.
- Code Era and Programming Assistant: Giant Language Fashions (LLM) for code era have a lot to realize from GRPO, enabling the LLM to group related programming contexts to optimize their coaching course of. The mannequin can specialize for programming languages, coding patterns, and complexity whereas implementing requirements throughout entire teams.
- Instructional Content material Era: Anytime schooling is concerned, GRPO can develop an individualized studying expertise for every scholar. By creating teams primarily based upon studying fashion, subject material, and ability stage, GRPO can focus its consideration on optimizing the content material era to be highest high quality for that group of scholars, whereas nonetheless adhering to the tutorial requirements as an entire.
- Analysis and Scientific Assist: Analysis primarily based LLM’s use GRPO to optimally steadiness with respect to factual accuracy, creativity, and both basic or discipline-specific information. From its grouping capacities LLM’s are in a position to achieve specialization in wealthy information domains, whereas retaining skilled efficiency high quality in all phases.
Conclusion
GRPO is greater than one other optimization step; it marks a shift towards context-aware RL, enabling sensible advances for LLMs. DeepSeek-R1 confirmed how GRPO delivers steady, safe, real-world efficiency, shifting AI from easy sample matching to reasoning methods. By optimizing throughout contextually related teams, GRPO addresses core LLM challenges of pattern effectivity, stability, and relative efficiency. Its potential is huge, providing a path to steadiness specialization with consistency as AI workflows evolve.
Gen AI Intern at Analytics Vidhya
Division of Pc Science, Vellore Institute of Know-how, Vellore, India
I’m at the moment working as a Gen AI Intern at Analytics Vidhya, the place I contribute to modern AI-driven options that empower companies to leverage knowledge successfully. As a final-year Pc Science scholar at Vellore Institute of Know-how, I deliver a stable basis in software program improvement, knowledge analytics, and machine studying to my function.
Be at liberty to attach with me at [email protected]
Login to proceed studying and revel in expert-curated content material.