

{kind=link}
In an period the place knowledge is the lifeblood of medical development, the scientific trial {industry} finds itself at a important crossroads. The present panorama of scientific knowledge administration is fraught with challenges that threaten to stifle innovation and delay life-saving therapies.
As we grapple with an unprecedented deluge of knowledge—with a typical Part III trial now producing a staggering 3.6 million knowledge factors, which is 3 times greater than 15 years in the past, and greater than 4000 new trials licensed annually—our present knowledge platforms are buckling below the pressure. These outdated programs, characterised by knowledge silos, poor integration, and overwhelming complexity, are failing researchers, sufferers, and the very progress of medical science. The urgency of this example is underscored by stark statistics: about 80% of scientific trials face delays or untimely termination resulting from recruitment challenges, with 37% of analysis websites struggling to enroll sufficient individuals.
These inefficiencies come at a steep price, with potential losses starting from $600,000 to $8 million every day a product’s growth and launch is delayed. The scientific trials market, projected to achieve $886.5 billion by 2032 [1], calls for a brand new technology of Scientific Information Repositories (CDR).
Reimagining Scientific Information Repositories (CDR)
Usually, scientific trial knowledge administration depends on specialised platforms. There are numerous causes for this, ranging from the standardized authorities’ submission course of, the consumer’s familiarity with particular platforms and programming languages, and the power to depend on the platform vendor to ship area data for the {industry}.
With the worldwide harmonization of scientific analysis and the introduction of regulatory-mandated digital submissions, it is important to grasp and function throughout the framework of world scientific growth. This entails making use of requirements to develop and execute architectures, insurance policies, practices, pointers, and procedures to handle the scientific knowledge lifecycle successfully.
A few of these processes embody:
- Information Structure and Design: Information modeling for scientific knowledge repositories or warehouses
- Information Governance and Safety: Requirements, SOPs, and pointers administration along with entry management, archiving, privateness, and safety
- Information High quality and Metadata administration: Question administration, knowledge integrity and high quality assurance, knowledge integration, exterior knowledge switch, together with metadata discovery, publishing, and standardization
- Information Warehousing, BI, and Database Administration: Instruments for knowledge mining and ETL processes
These parts are essential for managing the complexities of scientific knowledge successfully.
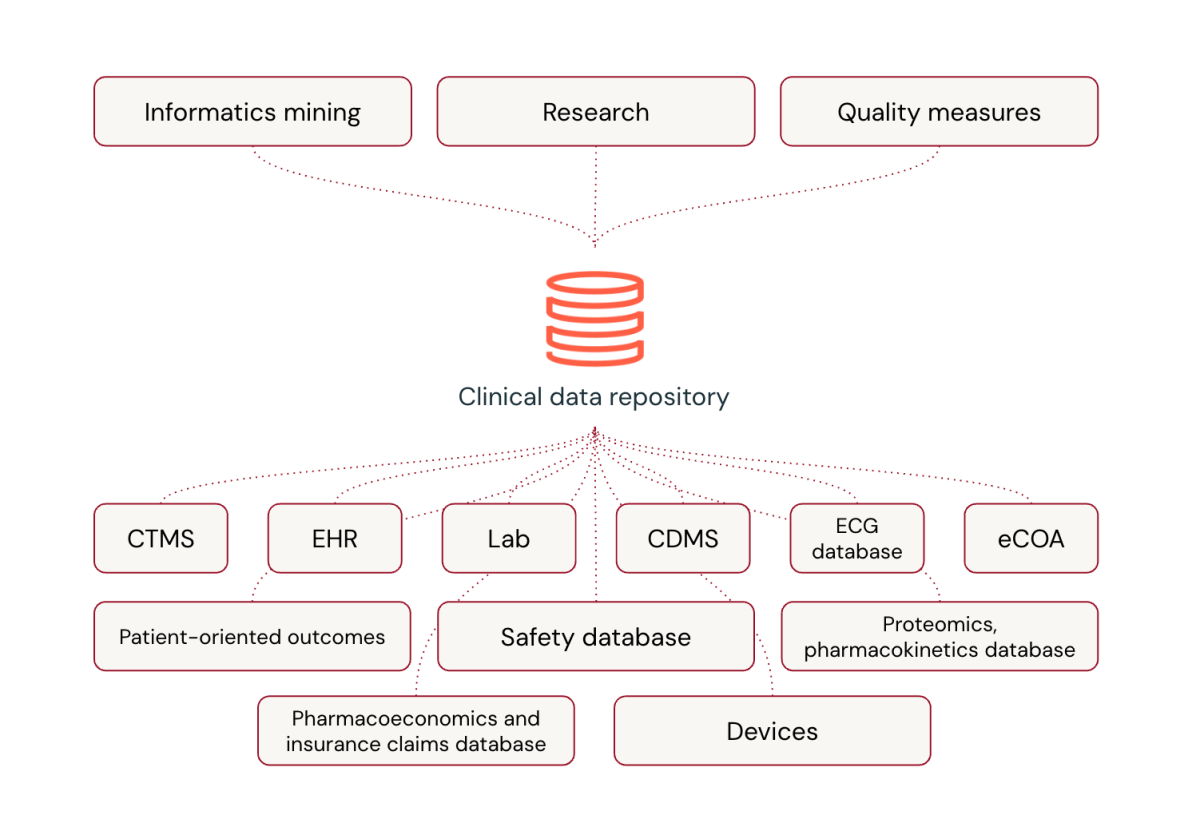
Common platforms are reworking scientific knowledge processing within the pharmaceutical {industry}. Whereas specialised software program has been the norm, common platforms provide important benefits, together with the pliability to include novel knowledge varieties, close to real-time processing capabilities, integration of cutting-edge applied sciences like AI and machine studying, and sturdy knowledge processing practices refined by dealing with huge knowledge volumes.
Regardless of considerations about customization and the transition from acquainted distributors, common platforms can outperform specialised options in scientific trial knowledge administration. Databricks, for instance, is revolutionizing how Life Sciences corporations deal with scientific trial knowledge by integrating various knowledge varieties and offering a complete view of affected person well being.
In essence, common platforms like Databricks should not simply matching the capabilities of specialised platforms – they’re surpassing them, ushering in a brand new period of effectivity and innovation in scientific trial knowledge administration.
Leveraging the Databricks Information Intelligence Platform as a basis for CDR
The Databricks Information Intelligence Platform is constructed on high of lakehouse structure. Lakehouse structure is a contemporary knowledge structure that mixes the most effective options of information lakes and knowledge warehouses. This corresponds nicely to the wants of the trendy CDR.
Though most scientific trial knowledge signify structured tabular knowledge, new knowledge modalities like imaging and wearable units are gaining reputation. They’re the brand new method of redefining the scientific trials course of. Databricks is hosted on cloud infrastructure, which provides the pliability of utilizing cloud object storage to retailer scientific knowledge at scale. It permits storing all knowledge varieties, controlling prices (older knowledge may be moved to the colder tiers to save lots of prices however accommodate regulatory necessities of retaining knowledge), and knowledge availability and replication. On high of this, utilizing Databricks because the underlying know-how for CDR permits one to maneuver to the agile growth mannequin the place new options may be added in managed releases in opposition to Large Bang software program model updates.
The Databricks Information Intelligence Platform is a full-scale knowledge platform that brings knowledge processing, orchestration, and AI performance to 1 place. It comes with many default knowledge ingestion capabilities, together with native connectors and probably implementing customized ones. It permits us to combine CDR with knowledge sources and downstream functions simply. This skill supplies flexibility and end-to-end knowledge high quality and monitoring. Native assist of streaming permits to counterpoint CDR with IoMT knowledge and achieve close to real-time insights as quickly as knowledge is out there. Platform observability is an enormous matter for CDR not solely due to strict regulatory necessities but additionally as a result of it permits secondary use of information and the power to generate insights, which finally can enhance the scientific trial course of total. Processing scientific knowledge on Databricks permits for implementation of the versatile options to achieve perception into the method. As an example, is processing MRI photographs extra resource-consuming than processing CT take a look at outcomes?
Implementing a Scientific Information Repository: A Layered Method with Databricks
Scientific Information Repositories are refined platforms that combine the storage and processing of scientific knowledge. Lakehouse medallion structure, a layered strategy to knowledge processing, is especially well-suited for CDRs. This structure usually consists of three layers, every progressively refining knowledge high quality:
- Bronze Layer: Uncooked knowledge ingested from varied sources and protocols
- Silver Layer: Information conformed to straightforward codecs (e.g., SDTM) and validated
- Gold Layer: Aggregated and filtered knowledge prepared for assessment and statistical evaluation
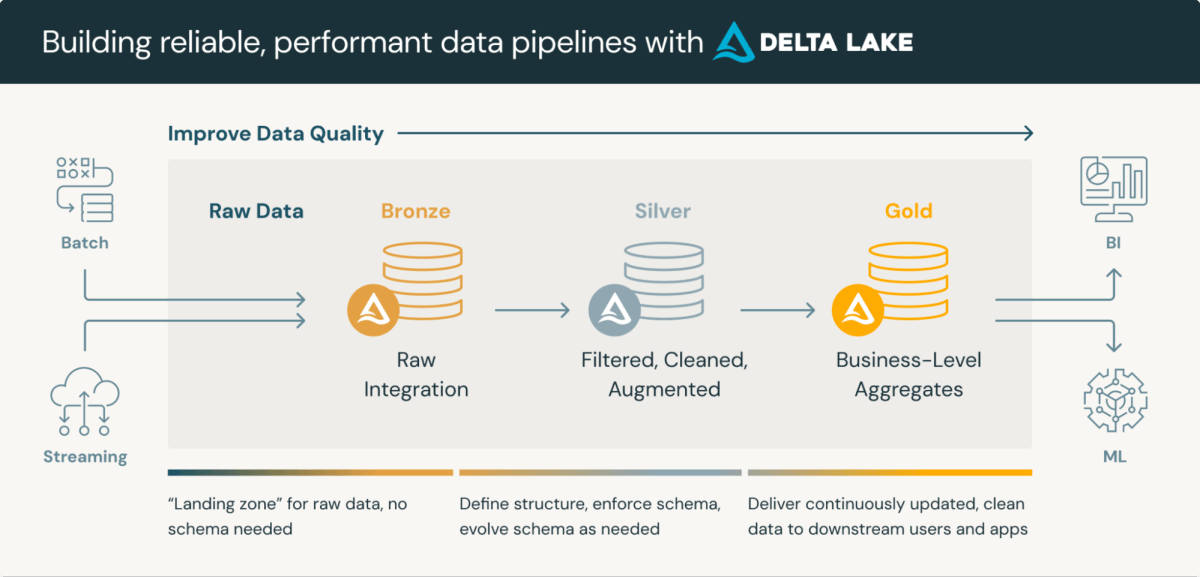
Using Delta Lake format for knowledge storage in Databricks presents inherent advantages similar to schema validation and time journey capabilities. Whereas these options want enhancement to totally meet regulatory necessities, they supply a stable basis for compliance and streamlined processing.
The Databricks Information Intelligence Platform comes geared up with sturdy governance instruments. Unity Catalog, a key element, presents complete knowledge governance, auditing, and entry management throughout the platform. Within the context of CDRs, Unity Catalog permits:
- Monitoring of desk and column lineage
- Storing knowledge historical past and alter logs
- Wonderful-grained entry management and audit trails
- Integration of lineage from exterior programs
- Implementation of stringent permission frameworks to stop unauthorized knowledge entry
Past knowledge processing, CDRs are essential for sustaining information of information validation processes. Validation checks needs to be version-controlled in a code repository, permitting a number of variations to coexist and hyperlink to totally different research. Databricks helps Git repositories and established CI/CD practices, enabling the implementation of a strong validation test library.
This strategy to CDR implementation on Databricks ensures knowledge integrity and compliance and supplies the pliability and scalability wanted for contemporary scientific knowledge administration.

The Databricks Information Intelligence Platform inherently aligns with FAIR rules of scientific knowledge administration, providing a complicated strategy to scientific growth knowledge administration. It enhances knowledge findability, accessibility, interoperability, and reusability whereas sustaining sturdy safety and compliance at its core.
Challenges in Implementing Fashionable CDRs
No new strategy comes with out challenges. Scientific knowledge administration depends closely on SAS, whereas modem knowledge platforms primarily make the most of Python, R, and SQL. This clearly introduces not solely technical disconnect but additionally extra sensible integration challenges. R is a bridge between two worlds — Databricks companions with Posit to ship first-class R expertise for R customers. On the similar time, integrating Databricks with SAS is feasible to assist migrations and transition. Databricks Assistant permits customers who’re much less acquainted with the actual language to get the assist required to jot down high-quality code and perceive the present code samples.
An information processing platform constructed on high of a common platform will at all times be behind in implementing domain-specific options. Robust collaboration with implementation companions helps mitigate this danger. Moreover, adopting a consumption-based worth mannequin requires further consideration to prices, which should be addressed to make sure the platform’s monitoring and observability, correct consumer coaching, and adherence to finest practices.
The largest problem is the general success charge of a majority of these implementations. Pharma corporations are continuously trying into modernizing their scientific trial knowledge platforms. It’s an interesting space to work on to shorten the scientific trial length or discontinue trials that aren’t more likely to turn out to be profitable quicker. The quantity of information collected now by the typical pharma firm comprises an unlimited quantity of insights which are solely ready to be mentioned. On the similar time, nearly all of such tasks fail. Though there isn’t any silver bullet recipe to make sure a 100% success charge, adopting a common platform like Databricks permits implementing CDR as a skinny layer on high of the present platform, eradicating the ache of widespread knowledge and infrastructure points.
What’s subsequent?
Each CDR implementation begins with the stock of the necessities. Though the {industry} follows strict requirements for each knowledge fashions and knowledge processing, understanding the boundaries of CDR in each group is crucial to make sure challenge success. Databricks Information Intelligence Platform can open many extra capabilities to CDR; that’s why understanding the way it works and what it presents is required. Begin with exploring Databricks Information Intelligence Platform. Unified governance with Unity Catalog, knowledge ingestion pipelines with Lakeflow, knowledge intelligence suite with AI/BI and AI capabilities with Mosaic AI shouldn’t be unknown phrases to implement a profitable and future-proof CDR. Moreover, integration with Posit and superior knowledge observability functionally ought to open up the potential for CDR as a core of the Scientific knowledge ecosystem quite than simply one other a part of the general scientific knowledge processing pipeline.
Increasingly more corporations are already modernizing their scientific knowledge platforms by using trendy architectures like Lakehouse. However the massive change is but to come back. The enlargement of Generative AI and different AI applied sciences is already revolutionizing different industries, whereas the pharma {industry} is lagging behind due to regulatory restrictions, excessive danger, and worth for the flawed outcomes. Platforms like Databricks enable cross-industry innovation and data-driven growth to scientific trials and create a brand new mind-set about scientific trials typically.
Get began at this time with Databricks.
Quotation:
[1] Scientific Trials Statistics 2024 By Phases, Definition, and Interventions
[2] Lu, Z., & Su, J. (2010). Scientific knowledge administration: Present standing, challenges, and future instructions from {industry} views. Open Entry Journal of Scientific Trials, 2, 93–105. https://doi.org/10.2147/OAJCT.S8172
Study extra in regards to the Databricks Information Intelligence Platform for Healthcare and Life Sciences.